
Federated Learning
Train AI models collaboratively—without sharing raw data. A privacy-preserving innovation that powers smarter, safer AI.
What is Federated Learning?
A groundbreaking machine learning paradigm that allows collaborative AI model training across multiple parties—without ever sharing raw data.
Federated Learning is an innovative decentralized machine learning technique that enables multiple parties to train a shared AI model without transferring raw data. This approach directly tackles the critical issues of data privacy and security found in conventional centralized learning frameworks.
Unlike traditional machine learning, which requires centralizing all data on a single server, Federated Learning distributes the training process across multiple endpoints or institutions. Only model updates (e.g., weights) are shared and aggregated—raw data never leaves the local device. This greatly reinforces data privacy and security while still enabling collaborative intelligence.
This groundbreaking learning framework safeguards user privacy, minimizes network load from large data transfers, and taps into the wealth of decentralized data to build stronger, more versatile AI models.
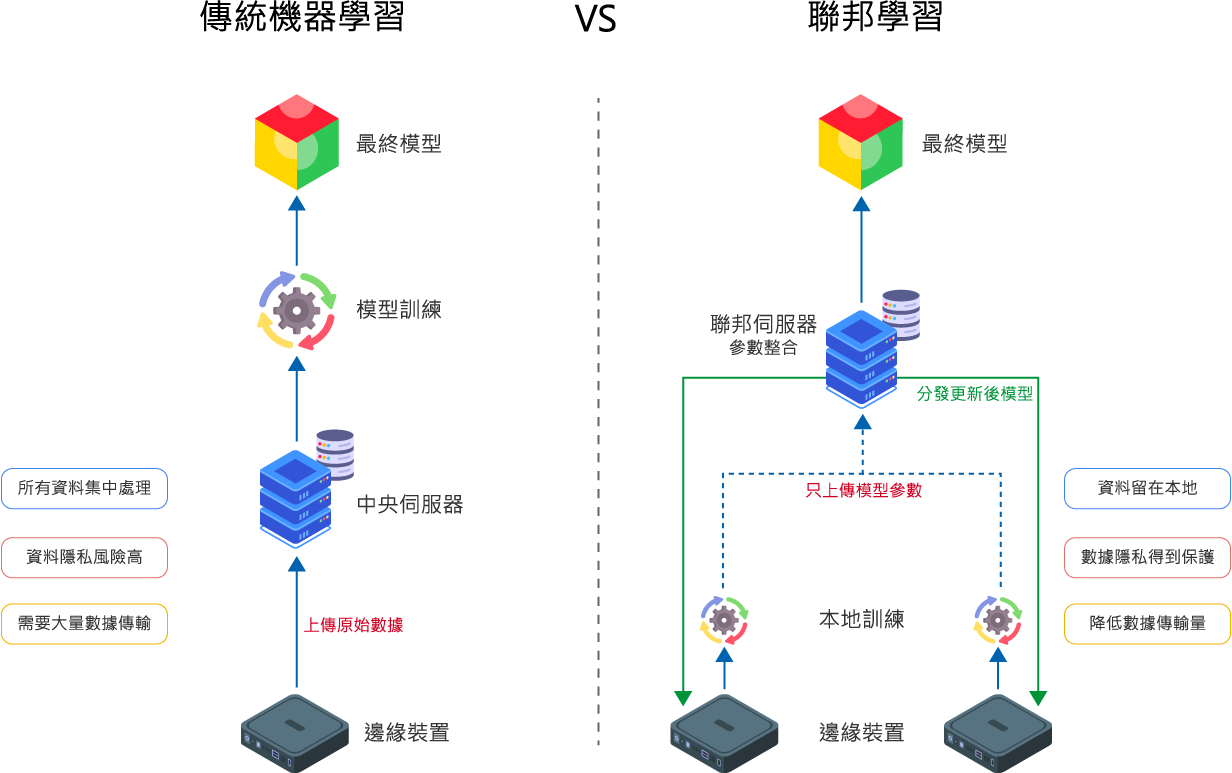
How Does Federated Learning Work?
Discover the Key Concepts and Operational Flow of Federated Learning
1
Model Initialization
The central server initializes a global model and distributes it to all participating clients for training.
2
Local Training
Each client trains the model using its local data and computes model updates (such as gradients or weights).
3
Parameter Upload
The client uploads the trained model parameters (not the raw data) to the central server.
4
Parameter Aggregation
The central server aggregates the model parameters from all clients to update the global model.
5
Model Distribution
The central server redistributes the updated global model to all clients, initiating the next round of training.
Key Advantages of Federated Learning
Discover the Diverse Benefits of Federated Learning for Enterprises and Edge AI

Safeguarding Data Privacy
Raw data always remains on local devices or within the organization, eliminating the need to upload it to a central server and significantly reducing the risk of data breaches.

Break Down Data Silos
Enables different organizations to collaborate without sharing raw data, effectively addressing the issue of data silos.

Regulatory Compliance
Helps organizations comply with data protection regulations such as GDPR and HIPAA, reducing legal barriers associated with cross-border data transfers.

Network Efficiency
Reduces data transmission volume by sending only model parameters instead of the entire dataset, lowering bandwidth requirements and communication costs.
Broaden the Variety of Data Sources
Enables training on diverse, distributed data sources to improve the model's generalization and robustness.

Instant Model Updates
Supports continuous learning and updating of models, enabling AI applications to adapt to ever-changing environments and user needs.