
聯邦學習
無需共享原始數據,在保護隱私的同時實現多方協作AI模型訓練的創新技術
什麼是聯邦學習 ?
一種革命性的機器學習方法,讓多方在不共享原始數據的情況下共同訓練AI模型
聯邦學習(Federated Learning)是一種分散式機器學習方法,它允許多個參與方在不交換原始數據的情況下共同訓練人工智能模型。旨在解決傳統集中式機器學習中的數據隱私和安全問題。
在傳統的機器學習過程中,所有數據需要集中到一個中央服務器進行處理和訓練。而在聯邦學習中,模型訓練過程被分散到多個終端設備或機構中進行,只有模型參數(如權重)會被傳輸和彙總,原始數據則留在本地,從而大大增強了數據隱私和安全性。
這種創新的學習範式不僅保護了用戶的數據隱私,還減少了大量數據傳輸帶來的網絡負擔,同時能夠利用分散在各個終端的豐富數據資源,訓練出更加強大和通用的AI模型。
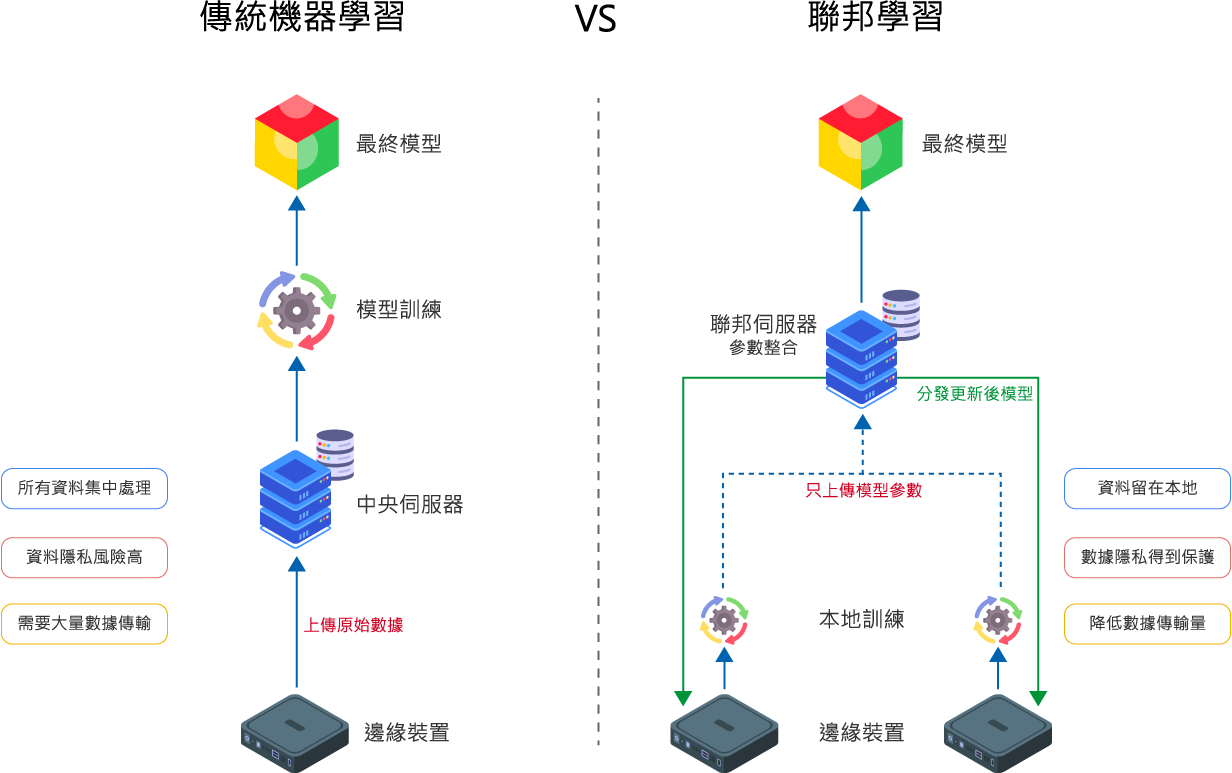
聯邦學習如何運作?
了解聯邦學習的核心工作原理和流程
1
模型初始化
中央服務器初始化一個全局模型,並將其分發給參與訓練的各個客戶端。
2
本地訓練
每個客戶端使用本地數據對模型進行訓練,計算模型更新(梯度或權重)。
3
參數上傳
客戶端將訓練產生的模型參數(非原始數據)上傳至中央服務器。
4
參數聚合
中央服務器聚合來自各個客戶端的模型參數,更新全局模型。
5
模型分發
中央服務器將更新後的全局模型重新分發給各個客戶端,開始下一輪訓練。
聯邦學習的關鍵優勢
探索聯邦學習為企業和邊緣 AI 帶來的多重價值

數據隱私保護
原始數據始終保留在本地設備或機構中,不需要上傳到中央服務器,大大降低了數據洩露的風險。

打破數據孤島
允許不同組織在不共享原始數據的前提下進行協作,解決數據孤島問題。

法規合規
幫助組織遵守 GDPR、HIPAA 等數據保護法規,減少跨境數據傳輸的法律障礙。

網絡效率
減少數據傳輸量,只需傳輸模型參數而非全部數據,降低帶寬需求和通信成本。
提升數據多樣性
能夠利用分散在各地的多樣化數據進行訓練,提高模型的泛化能力和魯棒性。

即時模型更新
支持模型的持續學習和更新,使 AI 應用能夠適應不斷變化的環境和用戶需求。